
Using tweets to improve an automatic speech recognizer
Using tweets to improve an automatic speech recognizer.
Abstract
Automatic speech recognition systems (ASRs) convert spoken words into text. They will convert speech into sequences of word sounds, and then decipher the correct word from these sounds. Experts determine how certain words sound, but how people actually pronounce words in conversation might differ from what an expert has determined.
Twitter tweets, however, might provide ideas for how words are pronounced. Given a 140 character limit, twitter users are forced to shorten their words in creative ways while still hinting at the original word. Because they tend to keep the parts of a word that matter the most, the final sequence of characters suggests the word’s pronunciation.
The Problem
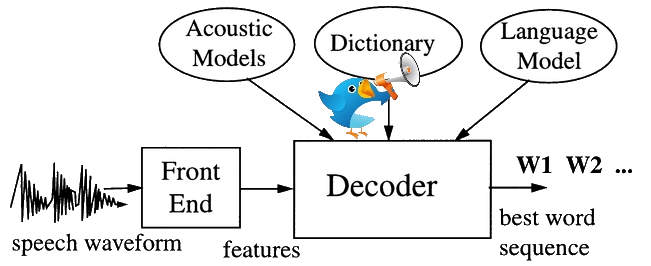
Automatic speech recognizers (ASRs) convert spoken language to text by mapping audio to phonetic pronunciations and then to words. Those pronunciations are typically determined by linguistic experts — but real conversational speech often diverges from the expert-defined canonical forms.
Twitter offered an unusual window into this gap. Given a 140-character limit, users shorten words creatively while preserving enough phonetic structure that the original word remains recognizable. That constraint, it turns out, encodes informal pronunciation.
Approach
We used Brown clustering on raw tweet data to group words that were contextually interchangeable — words that appear in similar positions across sentences cluster together regardless of spelling variation. This gave us sets of related forms: standard spellings alongside abbreviated, phonetically-spelled, and contracted variants.

From these clusters, each team member developed an independent algorithm for inferring pronunciation. My approach: given a cluster of word variants with known pronunciations, find the longest common subsequence of phonemes across the expert-defined pronunciations in the cluster. That subsequence represents the sounds consistently preserved across informal variants — likely the phonetically load-bearing portion of the word.
Results
The final pronunciation variants did not produce measurable improvement in ASR accuracy on the test corpus. However, the methods for extracting pronunciation structure from informal text were the substantive contribution — a starting point for further work on data-driven pronunciation modeling from social media.
Role
Researcher. Responsible for KALDI toolkit setup and training, and the algorithm for pronunciation extraction via longest common phoneme subsequence.